I did advanced mathematics and chose physics as one of my elective subjects in school. Nowadays, I do a lot of work based around analytics and forecasting.
“We need to find the average of this.”
“That’s easy. I’ll do some more advanced stuff to really dial in the accuracy.”
“Awesome. What’s the timeframe?”
looks at million row dataset “To find the average? Like a month. Some of these numbers are mispelled words… Why are all these blank?”
“Oh, you’ll have to read this 45 page document that outlines the default values.”
And that’s how roffice maths works. Lots and lots of if conditions, query merges, and meetings with other teams trying to understand why they entered in the thing they entered. By the time the data wrangling phase is complete, you give zero fucks about doing more than supplying the average.
Oh, sorry the 45 page document is for something else. The only person who understands this dataset is Dave and he was made redundant 5 years ago. Anyway, can you get this done today?
Yup this is every job now. Wrangling numbers. The actual job or calculation could be done in days if less. But dealing with dirty information and playing detective which isnt even part of it is the sink hole of every job right now.
Until it introduces a bunch of mistakes of its own. AI as a test has failed in several industries before now. It’s been around much longer than you’d think and has been tested in the BG for a lonnng time with much fail to the result of disgust if you even bring it up. It’s nothing more than a novelty in writing that doesn’t require the need to run on tight, non rational numbers. Something of which no binary based, household (and most industry) computer is capable of.
Look up the Ariane 5 rocket disaster. It is the summary of floating point error that can result in disaster. This is the limitation that is present in all standard computers you’d be accessing today since the 1930’s.
(Also referred to as round off errors or truncation errors in avionics because of how common irrational numbers are in spatial navigation.)
If Timmy has 45 pages to read on a bus traveling an average speed of 35 mph with an mean stop distance being 0.7 kms how many stops will Timmy pass before this fucking meeting ends ?
That’s software development for you. Why is that weird value there? Because some guy, at some point, had checked for that and somehow it’s still relevant.
I know of a system that churns through literally millions of transactions representing millions of Euros every day, and their interface has load bearing typos (because Germans in the 90s were really bad at the Englishs).
Geez, that reminds me of a former colleague that, when asked for “the numbers,” would just send screenshots of tables in the ERP system instead of exporting them to a spreadsheet. What’s even worse, usually a lot of values were plain wrong, on one occasion more than half of them.
You mean mathematical examples? Or like examples of analytical outcomes? Keeping in mind the more analytics-heavy, the more it involves lots of sources, patterns, variables, and scenarios, but I could provide just a single example.
Edit: Oh, wait. If you’re referring to just averages… In forecasting I prefer, as a minimum, to do weighted averaging. This is where I’ll have a certain time period of cumulated historical data that provides a more stable base, however more weight is applied the more recent (relevant) the data is. This shows a more realistic average than a single snapshot of data that could be an outlier.
But speaking of outliers, I’d prefer to also apply weight to outlying data points that may skew the output, especially if sample size is low. Like 1, 2, 2, 76, 3, 2. That 76 obviously skews the “average”.
Above that, depending on what’s required, I’ll use a proper method. Like if someone wants to know on average how many trucks they need a day, I’ll utilise Poisson instead to get the number of trucks they need each day to meet service requirements, including acceptable queuing, during the day. Like how the popular Erlang formulas utilise Poisson distribution and can kind of handle 90% of BAU S&D loading in day to day operations with a couple clicks.
That’s a basic example, but as data cleanliness increases, those better steps can be taken. Could be like 25 average last Wed vs. 20 weighted average over last month vs. 16 actually needed if optimised correctly.
Oh, and if there’s data on each truck’s mileage, capacity, availability, traffic density in areas over the day, etc…obbioisly it can be even more optimised. Though I’d only go that far if things were consistent/routine. Script it, automate it, set and forget and have the day’s forecast appear in the warehouse each morning.
And yet such simple things are often incredibly hard to get done because of poor data governance or systems.


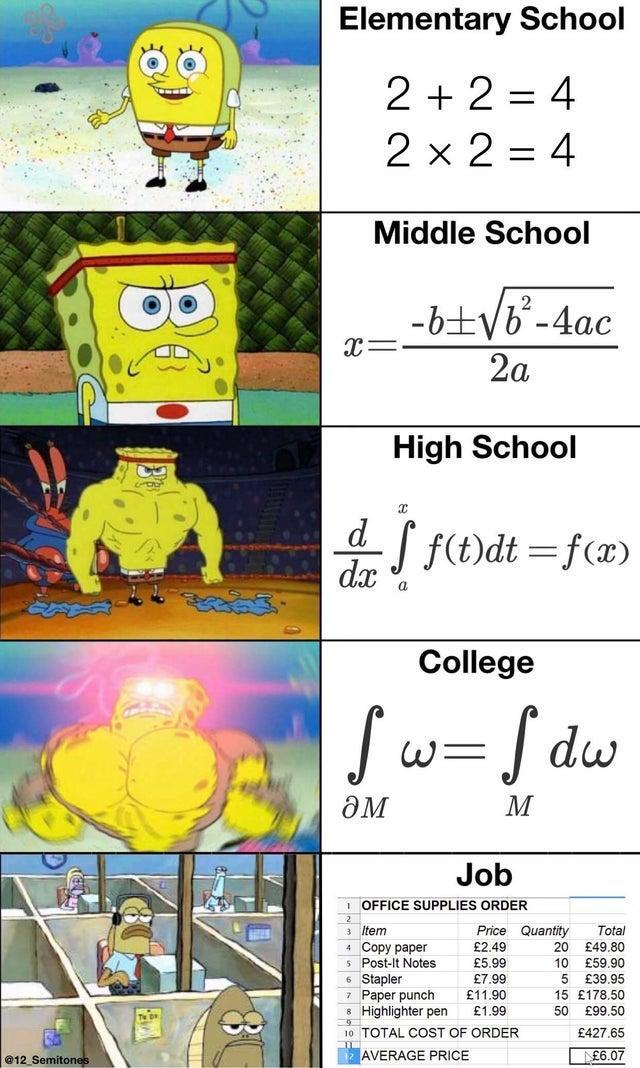{kind=link}
I did advanced mathematics and chose physics as one of my elective subjects in school. Nowadays, I do a lot of work based around analytics and forecasting.
“We need to find the average of this.”
“That’s easy. I’ll do some more advanced stuff to really dial in the accuracy.”
“Awesome. What’s the timeframe?”
looks at million row dataset “To find the average? Like a month. Some of these numbers are mispelled words… Why are all these blank?”
“Oh, you’ll have to read this 45 page document that outlines the default values.”
And that’s how roffice maths works. Lots and lots of if conditions, query merges, and meetings with other teams trying to understand why they entered in the thing they entered. By the time the data wrangling phase is complete, you give zero fucks about doing more than supplying the average.
Oh, sorry the 45 page document is for something else. The only person who understands this dataset is Dave and he was made redundant 5 years ago. Anyway, can you get this done today?
Dang, I was really hoping this would be one of those stories that goes like:
“How long will that take?”
“It’s a lot of data…like a month?” (But I actually wrote a Python script that compiles and formats it perfectly in like 5 minutes.)
“You’re such a hard worker!”
Shhhh
Yup this is every job now. Wrangling numbers. The actual job or calculation could be done in days if less. But dealing with dirty information and playing detective which isnt even part of it is the sink hole of every job right now.
Lol, I have still written python scripts to deal with them all.
I miss those days…
Is this why chatgpt has a chance at optimizing work? Because it will filter out boring mistakes for you
Until it introduces a bunch of mistakes of its own. AI as a test has failed in several industries before now. It’s been around much longer than you’d think and has been tested in the BG for a lonnng time with much fail to the result of disgust if you even bring it up. It’s nothing more than a novelty in writing that doesn’t require the need to run on tight, non rational numbers. Something of which no binary based, household (and most industry) computer is capable of.
Look up the Ariane 5 rocket disaster. It is the summary of floating point error that can result in disaster. This is the limitation that is present in all standard computers you’d be accessing today since the 1930’s.
(Also referred to as round off errors or truncation errors in avionics because of how common irrational numbers are in spatial navigation.)
If Timmy has 45 pages to read on a bus traveling an average speed of 35 mph with an mean stop distance being 0.7 kms how many stops will Timmy pass before this fucking meeting ends ?
Why do I need to know what Timmy is up to, and how much he is reading?
That’s software development for you. Why is that weird value there? Because some guy, at some point, had checked for that and somehow it’s still relevant.
I know of a system that churns through literally millions of transactions representing millions of Euros every day, and their interface has load bearing typos (because Germans in the 90s were really bad at the Englishs).
I think the solution is 42
Geez, that reminds me of a former colleague that, when asked for “the numbers,” would just send screenshots of tables in the ERP system instead of exporting them to a spreadsheet. What’s even worse, usually a lot of values were plain wrong, on one occasion more than half of them.
What is the advanced stuff you can do if you don’t have garbage data?
That’s a tough question in analytics lol
You mean mathematical examples? Or like examples of analytical outcomes? Keeping in mind the more analytics-heavy, the more it involves lots of sources, patterns, variables, and scenarios, but I could provide just a single example.
Edit: Oh, wait. If you’re referring to just averages… In forecasting I prefer, as a minimum, to do weighted averaging. This is where I’ll have a certain time period of cumulated historical data that provides a more stable base, however more weight is applied the more recent (relevant) the data is. This shows a more realistic average than a single snapshot of data that could be an outlier.
But speaking of outliers, I’d prefer to also apply weight to outlying data points that may skew the output, especially if sample size is low. Like 1, 2, 2, 76, 3, 2. That 76 obviously skews the “average”.
Above that, depending on what’s required, I’ll use a proper method. Like if someone wants to know on average how many trucks they need a day, I’ll utilise Poisson instead to get the number of trucks they need each day to meet service requirements, including acceptable queuing, during the day. Like how the popular Erlang formulas utilise Poisson distribution and can kind of handle 90% of BAU S&D loading in day to day operations with a couple clicks.
That’s a basic example, but as data cleanliness increases, those better steps can be taken. Could be like 25 average last Wed vs. 20 weighted average over last month vs. 16 actually needed if optimised correctly.
Oh, and if there’s data on each truck’s mileage, capacity, availability, traffic density in areas over the day, etc…obbioisly it can be even more optimised. Though I’d only go that far if things were consistent/routine. Script it, automate it, set and forget and have the day’s forecast appear in the warehouse each morning.
And yet such simple things are often incredibly hard to get done because of poor data governance or systems.