
Hi everyone, I’ve been building my own log search server because I wasn’t satisfied with any of the alternatives out there and wanted a project to learn rust with. It still needs a ton of work but wanted to share what I’ve built so far.
The repo is up here: https://codeberg.org/Kryesh/crystalline
and i’ve started putting together some documentation here: https://kryesh.codeberg.page/crystalline/
There’s a lot of features I plan to add to it but I’m curious to hear what people think and if there’s anything you’d like to see out of a project like this.
Some examples from my lab environment:
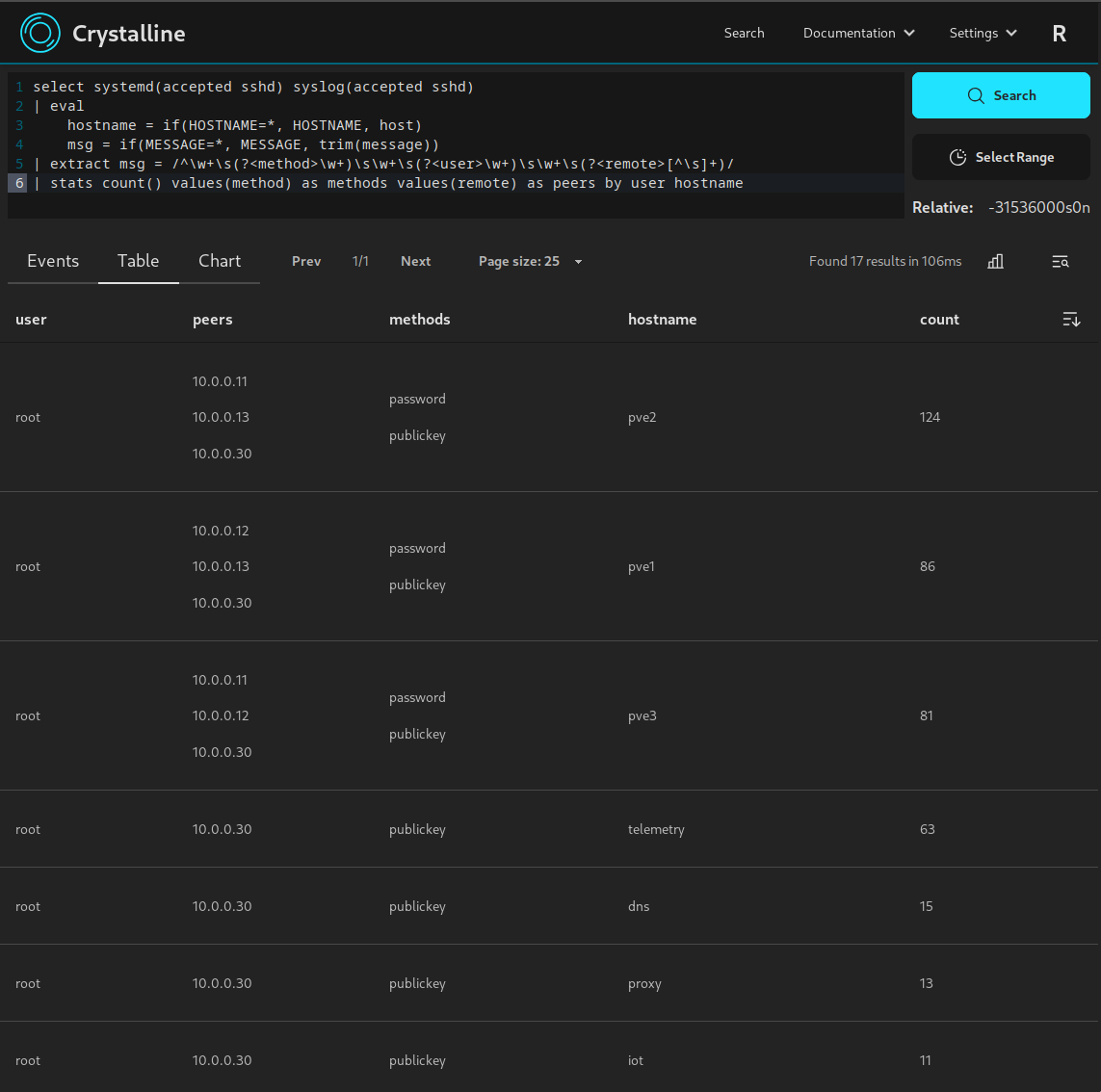
events view searching for SSH logins from systemd journals and syslog events:

counting raw event size for all indices:

performance is looking pretty decent so far, and it can be configured to not be too much of a resource hog depending on use case, some numbers from my test install:
- raw events ingested: ~52 million
- raw event size: ~40GB
- on disk size: ~5.8GB
Ram usage:
- not running searches ingesting 600MB-1GB per day it uses about 500MB of ram
- running the ssh search examples above brings it to about 600MB of ram while the search is running
- running last example search getting the size of all events (requires decompressing the entire event store) peaked at about 3.5GB of ram usage
I don’t really understand the point of this. What kind of logs are you storing and why would you want to?
Threat detection
Why do logs help with threat detection?
Applications like metrics because they’re good for doing statistics so you can figure out things like “is this endpoint slow” or “how much traffic is there”
Security teams like logs because they answer questions like “who logged in to this host between these times?” Or “when did we receive a weird looking http request”, basically any time you want to find specific details about a single event logs are typically better; and threat hunting does a lot of analysis on specific one time events.
Logs are also helpful when troubleshooting, metrics can tell you there’s a problem but in my experience you’ll often need logs to actually find out what the problem is so you can fix it.
This looks nice, but there’s plenty free alternatives in this space which warrants a section in the readme with the comparison to other products.
You mention ram usage, but it’s oftentimes a product of event size. Based on your numbers, your average event size is about 800 bytes. Let’s call it 1kb. That’s one million events per day. It’s surely sounds more promising than Elastic, but not reaching Loki numbers, or, if you focus on efficiency, is way behind Victoriametrics Logs (based on peeking at their benches).
I think the important bits you need to add is how you store the logs (i.e. which indices you build) and what are your trade-offs. Grep is an efficient logs processor which barely uses any ram but incurs dramatic I/O costs, after all.
Enterprises will be looking at different numbers and they have lots of SaaS products to choose from. Homelab users are absolutely your target audience and you can have it by making a better UI than the alternative (victoriametrics logs aren’t that comfortable to work with) or making resource usage lower (people run k8s clusters on RPis, they sure wonder about every megabyte of ram lost) or making the deployment easier (fire and forget, and when you come to it, it works).
It sounds like lots of things and I don’t want to be discouraging. What you started there is really nice-looking. Good job!

{kind=link}